

Delphyr behoort tot de best presterende klinische AI-systemen ter wereld

We hebben ons systeem getest met een van de de meest rigoureuze klinische AI-benchmarks beschikbaar. Dit zijn de resultaten.
Als je klinische beslissingen neemt met AI, heb je tools nodig die je kunt vertrouwen. Maar hoe weet je eigenlijk of een AI-systeem klaar is om clinici te ondersteunen? Het antwoord ligt steeds vaker in gestandaardiseerde, peer-reviewed benchmarks. Een benchmark is in wezen een gestandaardiseerd examen voor AI: een vaste set taken beoordeeld door experts, zodat verschillende systemen eerlijk en objectief kunnen worden vergeleken.
Een van de meest gerespecteerde benchmarks in healthcare AI is HealthBench Professional. We hebben Delphyr onlangs met deze benchmark beoordeeld. De resultaten bevestigen wat we in de praktijk al zagen: Delphyr presteert op het niveau van de beste frontier-modellen van vandaag, en op sommige onderdelen presteert het zelfs beter.
Wat is HealthBench Professional?
HealthBench Professional is een open benchmark ontwikkeld door onderzoekers bij OpenAI en gepubliceerd in 2026. De benchmark is specifiek ontworpen om te testen hoe goed AI-systemen kunnen reageren op en redeneren over de taken die clinici dagelijks uitvoeren. Denk hierbij aan het schrijven van een ontslagbrief, het opzoeken van een geneesmiddeleninteractie of het adviseren over een behandelplan. Oftewel: geen medische trivia-vragen, maar echte klinische werkzaamheden. De benchmark bestaat uit 525 cases die zijn opgesteld, verdeeld over drie klinische kernworkflows:
Klinisch schrijven en documentatie
Een groot deel van de dag van een clinicus gaat op aan administratie: vastleggen wat er tijdens een consult is gebeurd, een verwijsbrief opstellen of een ziekenhuisopname samenvatten voor het patiëntendossier. Deze categorie test of een AI-model dit soort gestructureerd, nauwkeurig klinisch schrijfwerk aankan. Oftewel: zet het de juiste informatie op de juiste plek, in taal waar andere zorgprofessionals mee uit de voeten kunnen.
Zorgconsultatie
Dit is de kern van wat artsen doen: uitzoeken wat er met een patiënt aan de hand is. Ze hebben informatie zoals klachten, testresultaten en medische voorgeschiedenis en vervolgens moeten ze nadenken over wat de oorzaak kan zijn, wat uitgesloten kan worden en wat de volgende stap is. Deze categorie test dus of een AI-model hetzelfde redeneerproces kan volgen: opties afwegen, risico's signaleren en tot een klinisch verantwoord advies komen.
Ondersteuning bij medisch onderzoek
Clinici moeten regelmatig iets opzoeken: wat zegt de laatste richtlijn over dit medicijn? Is er bewijs voor deze behandeling bij deze patiëntgroep? Deze categorie test of een AI de juiste informatie kan vinden, begrijpen wat die betekent en dit vertalen naar een bruikbaar antwoord.
Hoe de scoring werkt
Elk van de 525 cases is een realistische klinische situatie: een vraag of taak die een clinicus in de praktijk aan een AI-systeem zou stellen. Bijvoorbeeld: "wat is de aanbevolen eerstelijnsbehandeling voor deze aandoening?" of "kun je een verwijsbrief opstellen op basis van deze aantekeningen?"
Bij elke case hoort een rubric: een set van 2 tot 5 criteria opgesteld door praktiserende artsen. De standaard waaraan een AI-antwoord wordt gehouden, weerspiegelt dus wat een echte arts van een goed antwoord zou verwachten. Sommige criteria belonen specifieke klinische inhoud, zoals het correct noemen van een maximale veilige dosering of een bloeddrukgrens. Andere criteria leggen strafpunten op als het systeem een gevaarlijk of ongepast advies geeft.
Hoe Delphyr presteerde
We hebben Delphyr geëvalueerd op 441 Engelstalige cases uit de benchmark. De overige 84 cases zijn niet meegenomen omdat ze niet-Engelstalige inhoud bevatten (in het klinische scenario zelf of in de rubric). Omdat Delphyr is ontworpen voor Engelstalige klinische workflows, zou het behouden van deze cases geen zinvol of representatief resultaat hebben opgeleverd.
Het resultaat: een gemiddelde score van 58,3%, goed voor de tweede plaats van alle geëvalueerde systemen. Concreet betekent dit: Delphyr voldeed gemiddeld aan bijna 6 van de 10 criteria die een echte arts aan een goed antwoord zou stellen. Gezien de moeilijkheidsgraad van de taken, en het feit dat het hoogst gerangschikte systeem (GPT 5.4 for Clinicians) slechts 0,7 procentpunt hoger scoorde, plaatst dit Delphyr stevig in de top van de best presterende klinische AI-systemen ter wereld.
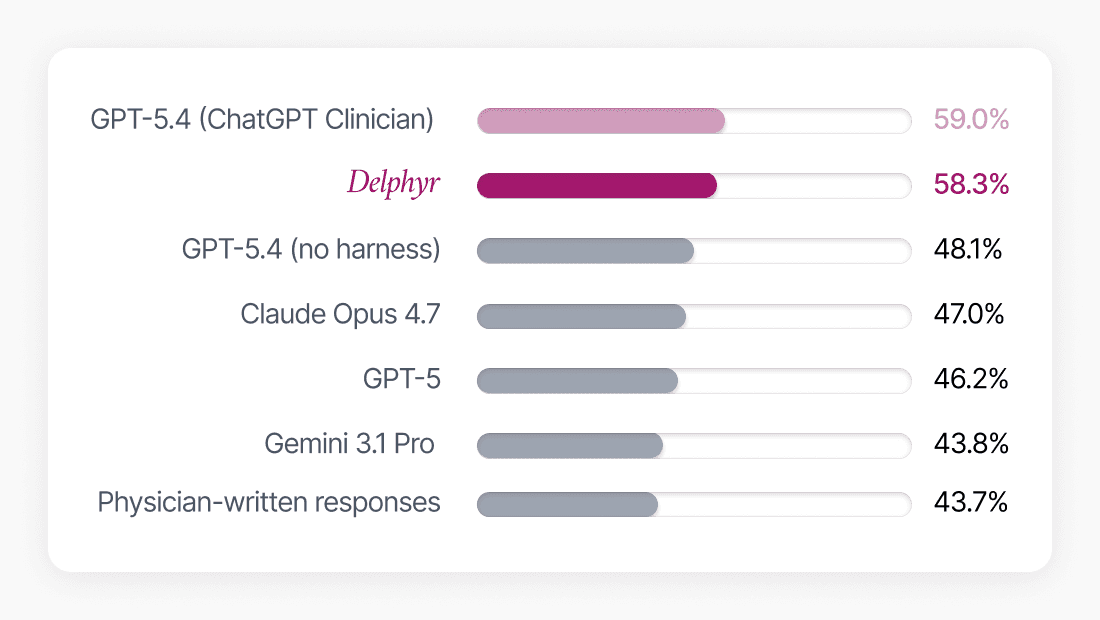
Een score die context vraagt
Het kan misschien verbazen dat antwoorden van echte artsen lager scoren dan AI-systemen op deze benchmark. Dat heeft alles te maken met hoe de scoring werkt. Elke case wordt beoordeeld aan de hand van een gedetailleerde rubric met meerdere specifieke criteria, en aan alle criteria voldoen vraagt een mate van systematische volledigheid die lastig te bereiken is bij natuurlijk schrijven.
De rubric kent punten toe aan elk criterium, ongeacht de context. Een arts die in de praktijk een antwoord geeft, richt zich op wat klinisch het meest relevant is en laat details weg die technisch correct maar vanzelfsprekend zijn (en scoort daardoor lager). AI-systemen produceren daarentegen langere, volledigere antwoorden die eerder elk vakje afvinken, niet omdat ze beter redeneren, maar omdat ze zijn geoptimaliseerd voor volledigheid. Een hoge benchmark-score weerspiegelt dus hoe goed een systeem gestructureerde criteria volgt (en dat is niet precies hetzelfde als hoe een goede arts denkt).
Het belang van architectuur
De vergelijking hierboven gaat over meer dan scores, het vertelt ook een verhaal over waarom AI die specifiek voor klinisch gebruik is gebouwd, beter presteert dan algemene modellen. De meeste algemene AI-modellen werken vanuit geheugen: ze genereren antwoorden op basis van patronen die tijdens de training zijn geleerd, zonder op dat moment een bron te raadplegen.
Delphyr werkt anders. Voordat het een antwoord genereert, doorzoekt het een samengestelde medische kennisbank, haalt de meest relevante klinische richtlijnen en evidence op, en bouwt vervolgens het antwoord op basis van die opgehaalde inhoud. Deze aanpak heet retrieval-augmented generation, oftewel RAG. Vergelijk het met het verschil tussen een arts die uit het hoofd antwoordt en een arts die eerst de laatste richtlijn raadpleegt.
Deze ontwerpkeuze heeft het sterkste voordeel bij documentatie- en onderzoekstaken. In klinisch schrijven en documentatie scoorde Delphyr 65,4%, beduidend hoger dan GPT-5.4 (34,6%), GPT-5 (28%) en GPT-5.2 (27,4%). Dit zijn taken die clinici voortdurend uitvoeren: ontslagbrieven opstellen, patiënt-notities samenvatten, gestructureerde rapportages produceren. Voor dat type werk maakt AI die put uit geverifieerde klinische content een concreet verschil ten opzichte van een model dat enkel op trainingsdata vertrouwt.
Hetzelfde voordeel is zichtbaar op het gebied van veiligheid. Op red-teaming cases (opzettelijk lastige prompts die het systeem moeten verleiden tot onveilige antwoorden) scoorde Delphyr 54,8%, beter dan meerdere frontier-modellen. Wanneer de kennisbank geen bewijs bevat dat een misleidende aanname ondersteunt, gaat Delphyr daar doorgaans niet in mee. Een algemeen model, dat puur op geheugen werkt, produceert eerder een antwoord dat plausibel klinkt maar klinisch niet verantwoord is.
Wat dit betekent voor clinici
Benchmarks zijn waardevol omdat ze transparant en reproduceerbaar zijn en worden ontworpen door clinici zijn (niet door AI-teams). Wanneer een systeem goed presteert op HealthBench Professional, slaagt het niet alleen voor een intern test, maar wordt het beoordeeld aan de hand van dezelfde strenge standaard die voor elk ander systeem in het veld geldt, inclusief die van de best gefinancierde AI-labs ter wereld.
De positie van Delphyr in de top twee, beter dan elk algemeen frontier-model, en binnen de statistische marge van het nummer één systeem, laat zien wat mogelijk is wanneer klinische kennis, gestructureerde retrieval en veiligheidsgaranties van meet af aan zijn ingebouwd in AI-platform, in plaats van achteraf toegevoegd.
Veelgebruikte begrippen in dit artikel
Benchmark: Een gestandaardiseerd examen voor AI-systemen: een vaste set taken beoordeeld door experts, zodat verschillende systemen eerlijk en objectief kunnen worden vergeleken.
Case: Een enkel testscenario in de benchmark: een realistische klinische vraag of taak die een clinicus aan een AI-systeem zou stellen, beoordeeld aan de hand van een scoreformulier opgesteld door praktiserende artsen.
Rubric: Een door artsen opgesteld beoordelingsformulier voor de evaluatie van een AI-antwoord op een case. Elk criterium heeft een puntwaarde: positief voor inhoud die nauwkeurig en klinisch gepast is, negatief voor alles wat schadelijk, misleidend of onvolledig is.
RAG (retrieval-augmented generation): Een AI-architectuur waarbij het systeem een samengestelde kennisbank doorzoekt voordat het een antwoord genereert, waardoor antwoorden zijn gebaseerd op actuele evidence in plaats van op wat het systeem tijdens de training heeft geleerd.
Frontier-model: Een geavanceerd algemeen AI-taalmodel zoals GPT-5 of Claude Opus, gebouwd voor breed gebruik en niet specifiek ontworpen voor klinische taken.