
Delphyr Scores Top Tier on HealthBench Professional

We put our system through one of the most rigorous clinical AI benchmarks available. Here's what we found.
When you're making clinical decisions with AI, you need tools you can trust. But how do you actually know whether an AI system is ready to support clinicians? The answer increasingly lies in standardised, peer-reviewed benchmarks. A benchmark is essentially a standardised exam for AI: a fixed set of tasks scored by experts, so different systems can be compared fairly and objectively.
One of the most respected benchmarks in healthcare AI today is HealthBench Professional. We recently ran Delphyr through this evaluation. The results confirm what we've seen in real-world use: Delphyr performs at the level of today's top frontier models (and in some areas, it beats them).
What is HealthBench Professional?
HealthBench Professional is an open benchmark developed by researchers at OpenAI and published in 2026. It's specifically designed to test how well AI systems can respond to and reason through the kinds of tasks clinicians actually perform every day; things like writing a discharge summary, looking up a drug interaction, or advising on a treatment plan (so, not just medical trivia or exam questions). The benchmark contains 525 physician-authored cases covering three core clinical workflows:
Clinical writing and documentation
Much of a clinician's day is spent on paperwork: writing up what happened during a patient visit, drafting a letter to refer a patient to a specialist, or summarising a hospital stay for the patient's file. This category therefore tests whether an AI can produce that kind of structured, accurate clinical writing. Or in other words: getting the right details in the right place, in language that other healthcare professionals can act on.
Care consultation
This category is about the core of what doctors do: figuring out what is wrong with a patient. They receive information about a patient — symptoms, test results, medical history — and need to work through what might be causing the problem, what to rule out, and what to do next. This category tests whether an AI model can follow that same reasoning process: weighing options, flagging risks, and arriving at a clinically sound recommendation.
Medical research support
Clinicians regularly need to look something up: what does the latest guideline say about this medication? Is there evidence for this treatment in this patient group? This category tests whether an AI can find the right evidence, understand what it means, and translate it into a useful answer for the clinician asking the question.
How the scoring works
Each of the 525 cases represents a realistic clinical scenario: a question or task that a clinician might actually bring to an AI system. For example: "what is the recommended first-line treatment for this condition?" or "can you draft a referral letter based on these notes?".
For each case, HealthBench Professional also provides a custom rubric. This is a set of 2–5 criteria written by real, practising physicians, meaning the standard each AI response is held to reflect what an actual doctor would expect from a good answer. Some criteria reward specific clinical content — for example, correctly citing a numeric limit like a maximum safe drug dose or a blood pressure target, beyond which a recommendation would be unsafe. Others apply penalties if the system gives a dangerous or inappropriate recommendation.
How Delphyr performed
We evaluated Delphyr on 441 English-language cases from the benchmark. The remaining 84 cases were excluded because they contained non-English content (either in the clinical scenario itself or in the scoring rubric). Since Delphyr is designed for English-language clinical workflows, including those cases would not have produced a meaningful or fair result.
The overall result: a mean score of 58.3%, placing Delphyr in second position out of all evaluated systems. To put that in plain terms: on average, Delphyr provided a response that met nearly 6 out of 10 of the criteria a real doctor would expect from a good answer. Given that these are genuinely difficult tasks — and that the top-ranked system (GPT 5.4 for Clinicians) scored just 0.7 percentage points higher — this places Delphyr squarely among the world's best-performing clinical AI systems today.
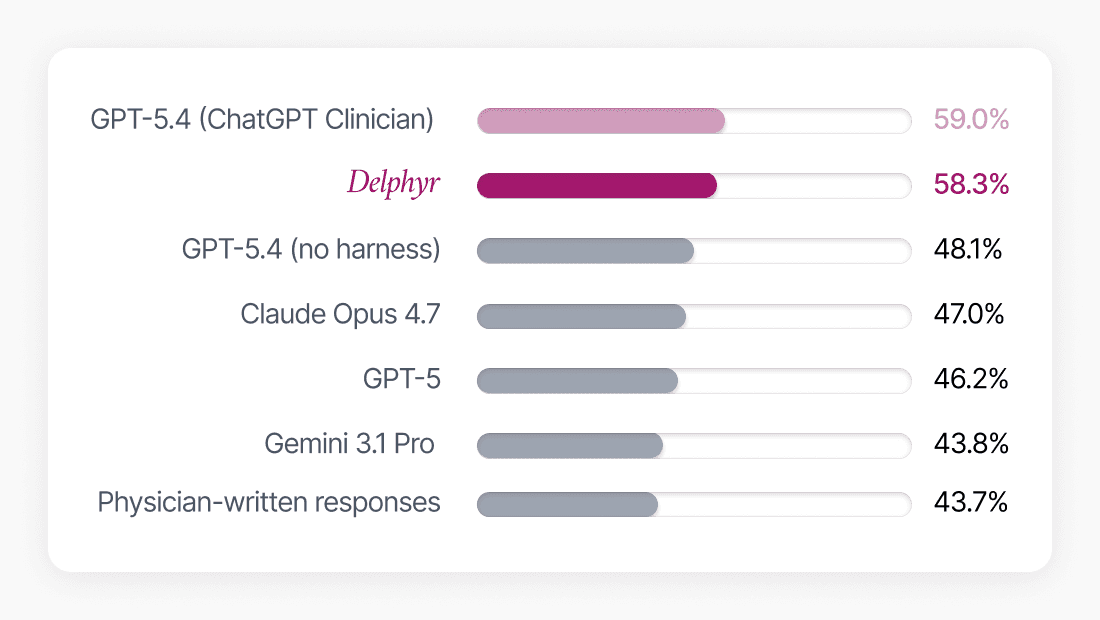
A score that needs context
It might seem surprising that responses written by real physicians score lower than AI systems on this benchmark. The reason comes down to how the scoring works. Each case is evaluated against a detailed rubric with multiple specific criteria, and hitting every single one of them requires a level of systematic completeness that is hard to achieve when writing naturally.
A physician giving a real-world answer will often focus on what matters most clinically, leaving out details that are technically correct but feel obvious or unnecessary to write down. The rubric, however, awards points for each criterion regardless of context. AI systems, by contrast, tend to produce longer and more exhaustive responses that are more likely to tick every box. Not necessarily because they reason better, but because they are optimised to be thorough. This is an important nuance: a high benchmark score reflects how well a system follows structured criteria, which is not exactly the same as how a good doctor thinks.
Why the architecture matters
Moreover, the comparison above isn't just about scores, it tells a story about why an AI system built specifically for clinical use outperforms general-purpose models that weren't. Most general-purpose AI models work from memory: they generate answers based on patterns learned during training, without checking a source in the moment.
Delphyr works differently. Before generating an answer, it first searches a curated medical knowledge base, retrieving the most relevant clinical guidelines and evidence, and then building its response from that retrieved content. This approach is called retrieval-augmented generation, or RAG. Think of it as the difference between a doctor who answers from memory and one who looks up the latest guideline before responding.
This design shows its clearest advantage in documentation and research tasks. In clinical writing and documentation, Delphyr scored 65.4. This is substantially higher than GPT-5.4 (34.6%), GPT-5 (28%), and GPT-5.2 (27.4%). These are tasks clinicians perform constantly: generating discharge letters, summarising patient notes, producing structured reports. For that workload, having an AI that pulls from verified clinical content rather than relying on what it was trained on makes a concrete difference.
The same advantage shows up in safety. On red-teaming cases (deliberately tricky prompts designed to push the system into giving unsafe answers) Delphyr scored 54.8%, above several of the frontier models. When the knowledge base doesn't contain evidence to support a misleading premise, Delphyr tends not to go along with it. A general-purpose model, drawing on memory alone, is more likely to produce an answer that sounds plausible but isn't clinically sound.
What this means for clinicians
Benchmarks matter because they are transparent, reproducible, and designed by clinicians rather than AI teams. When a system performs well on HealthBench Professional, it's not just passing an internal test, it's being evaluated against the same rigorous standard applied to every other system in the field, including the world's best-funded AI labs.
Delphyr’s position in the top two, ahead of every general-purpose model, and within statistical range of the number-one system, reflects what's possible when clinical knowledge, structured retrieval, and safety guardrails are built into an AI from the ground up rather than bolted on afterwards.
Key terms used in this article
Benchmark: A standardised exam for AI systems: a fixed set of tasks scored by experts, so different systems can be compared fairly and objectively.
Case: A single test scenario in the benchmark: a realistic clinical question or task that a clinician might bring to an AI system, evaluated against a scoring checklist written by practising physicians.
Rubric: A physician-written scoring checklist used to evaluate an AI's response to a case. Each criterion carries a point value: positive for content that is accurate and clinically appropriate, negative for anything harmful, misleading, or missing.
RAG (retrieval-augmented generation): An AI architecture where the system searches a curated knowledge base before generating its answer, grounding responses in up-to-date evidence rather than relying on what it learned during training.
Frontier model: A general-purpose AI language model at the leading edge of capability, such as GPT-5 or Claude Opus, built for broad use rather than designed specifically for clinical tasks.